基准测试的挑战
通过TAEF框架诊断的主要失败模式与困难任务分析
错误类型分布
表格理解错误
38%模型未能正确理解表格结构、表头关系或数据含义,导致错误的数据解释
问题理解偏差
36%模型对用户问题的理解出现偏差,回答与问题不相关或部分相关
表格定位错误
21%模型在多表环境中选择了错误的表格,或遗漏了必要的表格
累积传播错误
5%多轮对话中,前期错误在后续轮次中累积传播,导致最终结果错误
🔍 困难任务执行分析
📊
表格理解错误 & 累积传播错误
Code Error Caused by Table Comprehension | Cumulative Propagation Errors

错误分析图(待添加)
❌ 表格理解错误
模型在代码执行块之间未能保持状态,尝试引用之前块中定义的变量(all_data)而未重新加载,导致重复的NameError异常。
⚠️ 累积传播错误
最终报告建立在有缺陷的数据提取之上,将中间(错误)结论当作事实,导致分析结果完全偏离。
🎯
表格定位错误 & 问题理解偏差
Table Localization Error | Question Understanding Deviations
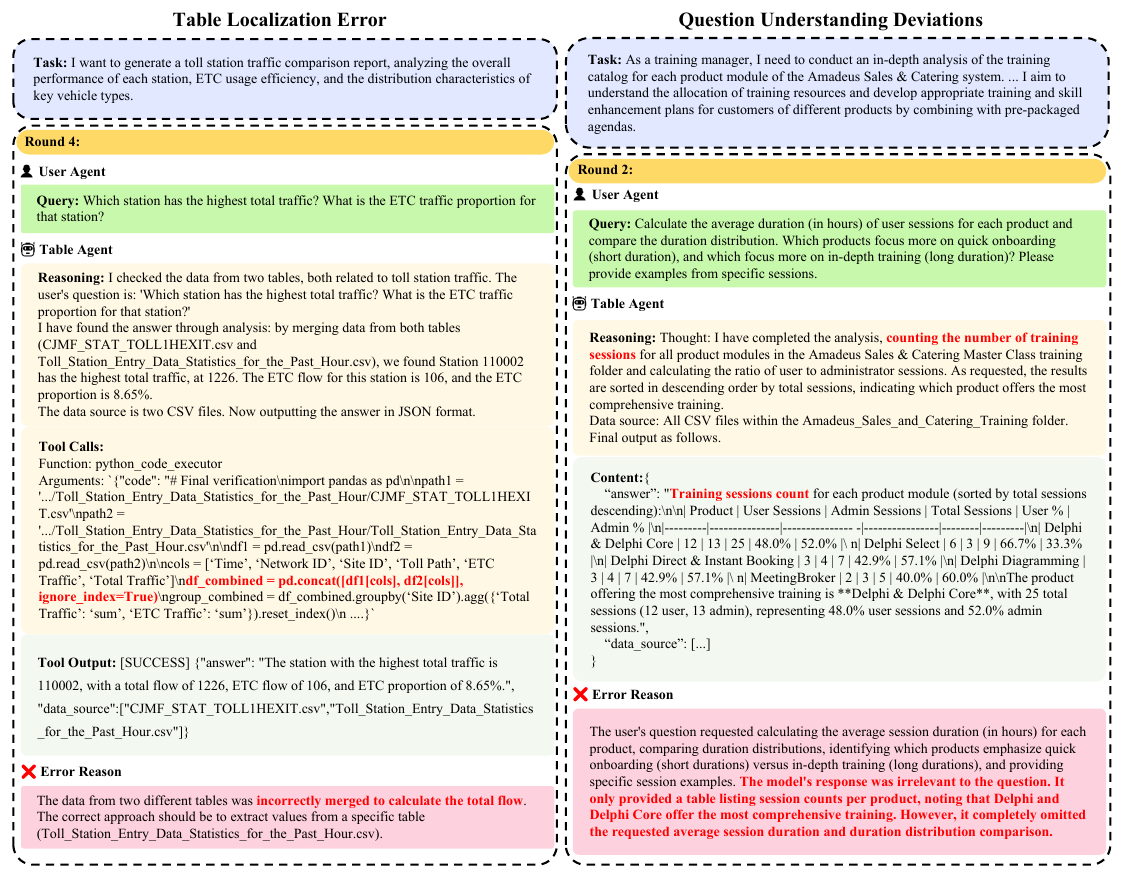
错误分析图(待添加)
🔍 表格定位错误
模型错误地将两个不同表格的数据合并计算总流量,而正确做法应仅从特定表格提取数值。
💬 问题理解偏差
用户要求计算平均会话时长并比较分布,模型却仅提供了会话数量统计表,完全遗漏了时长分析。